What the AI actually saw
Or: why Coffee Run reads coffee shops


Anyone can list the coffee shops in a city. Google has that. Yelp has that. There’s no product to build out of “here are the cafés near you” — that ground is taken, and it’s been taken for fifteen years.
The product I’m building only works if Coffee Run knows things about coffee shops that Google and Yelp don’t. Not different facts — different shape of facts. Yelp can tell you a café has four stars and is “good for working.” Coffee Run needs to know whether the place is plant-filled and quiet at 2pm and pours a $6 latte from a local roaster, because that’s what it takes to match a specific person to their best next cup of coffee. The whole thesis of the app — that discovery for indie coffee should look more like Letterboxd than Yelp — depends on having a model of each shop that is richer, more structured, and more opinionated than what’s available on the public internet.
That model is what gets built by the enrichment pipeline. This post is about how it works, what it gets wrong, and what I’ve learned from a month of iterating on it.
What the pipeline knows about one shop
WOOD Coffee Co. sits on 10th Street in Rose Park, Long Beach. Plant-based, queer-owned, opened in 2021 by Nolan Wood. I’ve been a few times. It’s good.
Here’s what Coffee Run knows about it, all of which was extracted automatically:
Founded in 2021 by Nolan Wood. LGBTQ+-owned. Plant-based by default — every drink defaults to oat or almond milk with no substitution charge.
Milk alternatives offered: oat, almond, pistachio, soy. (Pistachio is interesting. I’ll come back to that.)
Order at the counter. Mobile ordering available. No drive-thru.
Dog-friendly. Hosts community events and paint nights.
The vibe, per the photos: industrial, rustic, cozy, lively, modern, spacious — and plant-filled.
None of that was typed in by a human. No editor visited. The pipeline read WOOD’s website, looked at five photos pulled from Google Places, scanned review text, and wrote all of it. The description on the shop’s detail page in the app — also written by the model — reads:
This plant-based coffee shop fills a gap in Rose Park with lattes that run $3.50 and skip dairy entirely — no substitutions needed since everything defaults to oat or almond milk. The industrial-meets-rustic space draws locals who treat it like genuine community infrastructure, showing up for co-working sessions and paint nights alongside their morning cortados. Owner Nolan Wood built the spot as an LGBTQ+-centered gathering place that welcomes everyone, and the intentional programming makes it feel less like a café and more like the neighborhood anchor this stretch of 10th Street was missing.
That description is specific, accurate, and mentions the owner by name. None of it appears on WOOD’s Google or Yelp page in that form. That gap — between what’s publicly available and what the app actually needs to make a good recommendation — is the gap the pipeline is built to close.
How it works
Three passes, all running on Claude Haiku 4.5.
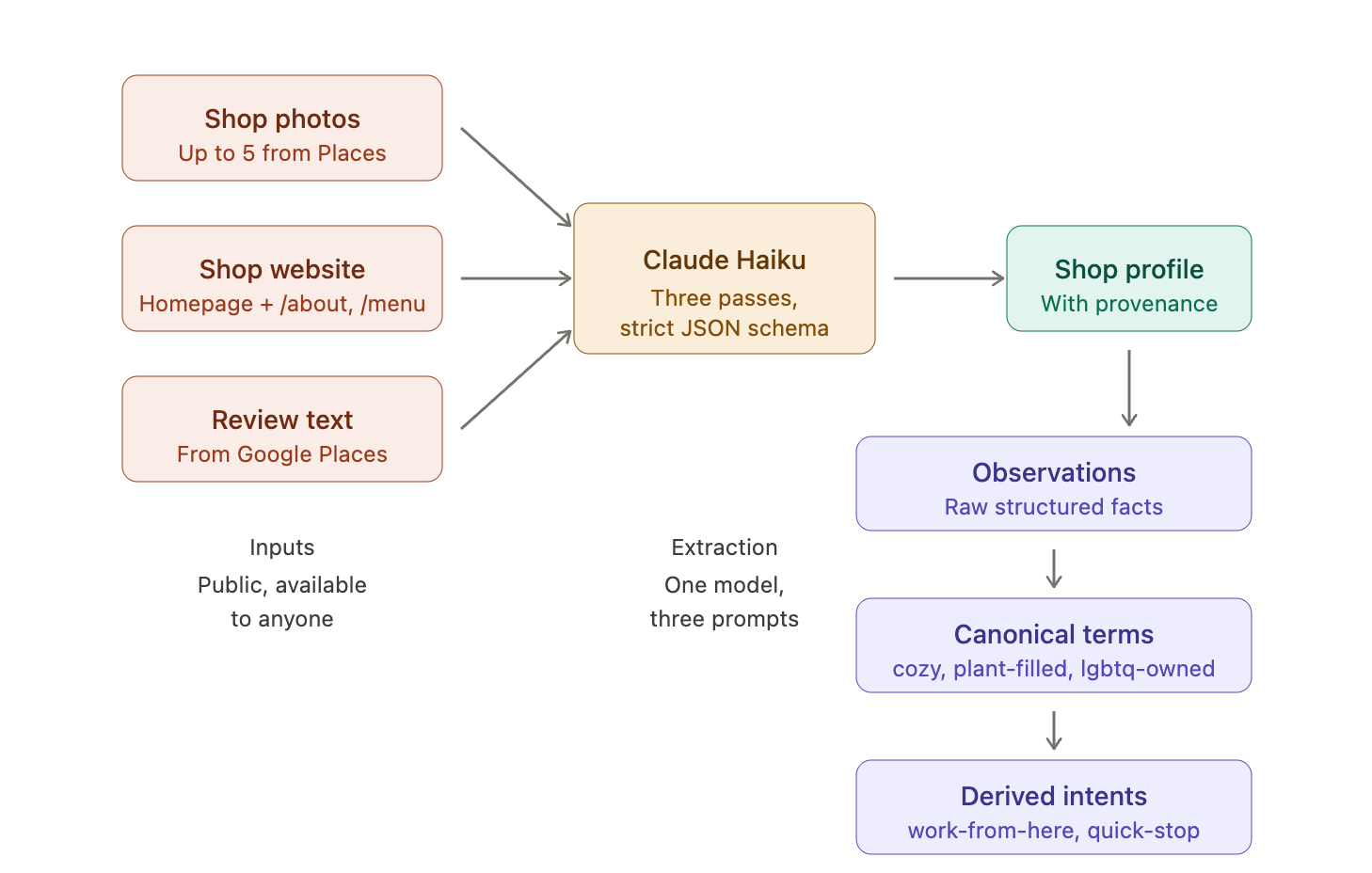
The vision pass sends up to five photos through Haiku and asks it to extract structured findings: vibes, equipment, menu board prices, visible roasters, seating, parking, even ethnic coffee traditions if they’re visible (phin filters, moka pots, cezve, Korean dessert cases). Before the photos go to Haiku, a pre-classifier filters out food close-ups — those don’t tell us anything about the shop, and they cost money. Every claim the vision pass makes has to cite which photo it came from and a one-line evidence string. No evidence, no claim.
The first-party pass walks the shop’s own website. It fetches the homepage plus a handful of well-known paths (/about, /menu, /hours, /our-story), strips out navigation and scripts, honors robots.txt, and asks Haiku to pull identity, values, policies, accessibility, service model, and the actual menu. The prompt is strict about what counts as authoritative: shop-authored prices and policies are reliable, but self-described vibes (”welcoming!” “community-focused!”) are flagged as marketing copy and weighted low. The shop telling you it’s cozy is not evidence that it’s cozy.
The review pass processes Google review text and produces a 2–4 sentence description, with hard rules against generic filler.
All three passes write into a single observations record on each shop, with a strict schema (drinks, roasters, equipment, seating, policies, identity, values, atmosphere). Every field carries a provenance record: which source it came from, when it was extracted, the confidence, a human-readable reason. There are 50,581 of those provenance records across the corpus right now. Every claim the app makes about every shop, sourced.
A separate step then maps observations to canonical taxonomy slugs — cozy, plant-filled, lgbtq-owned, dog-friendly — and intents like work-from-here, quick-stop, meet-a-friend are derived from those slugs. Three layers, getting progressively more opinionated: raw observations, canonical terms, derived intents.
That layered structure is the thing. The whole point is that the intents — “this is a good place to work” — are the surface the user eventually touches, but they’re derived from a model of the shop that’s much richer than any one signal. A work-from-here shop is not the same as a shop with a “good for working” Yelp tag. It’s a shop where the observed noise is conversation-friendly, the wifi is unlimited, the laptop policy isn’t peak-restricted, and the seating includes either window-seating or a communal table. The intent is an opinion, derived from a model. That’s the product.
What I got wrong, twice
Building this has not gone in a straight line. Two failures worth showing, because they’re the texture of what working on a metadata pipeline actually feels like.
Re-read WOOD’s description above. It says lattes run $3.50. They don’t. A standard latte at WOOD is $6.25. The vision pass saw some number on a menu board and decided it was the standard latte price — but $3.50 at a plant-based shop in 2026 should have been a smell test the pipeline failed. I caught it because I was writing this post, looked at the description, and the number didn’t ring true. I checked the menu manually and confirmed the bug. There’s now a Linear ticket open against it. Best guess on what happened: the model read a smaller drink price (a single espresso, a drip coffee), or — and this is the most likely — it read an old menu photo from years ago. WOOD opened in 2021; $3.50 is plausible for then. The fix is going to involve either much stricter evidence rules (”only return a latte price if the OCR’d text literally contains the word ‘Latte’”) or a sanity check against menu prices already in the corpus for similar shops.
But the more interesting point isn’t the fix. It’s how I caught it. I caught it because I happened to be writing about this exact shop and the number happened to look wrong to me. That’s not a process. There are 3,900 shops in the corpus. I cannot eyeball every claim about every shop. The cost of manual verification at corpus scale is exactly the editorial labor cost I’m building the pipeline to avoid — which means the pipeline itself has to get better at catching this class of error before it ships, because nothing downstream of it can.
A different Long Beach shop has a counter lined with color-coded drinks in branded cups — purple, green, pink. The vision pass looked at the photo and extracted menu items named “Purple/Berry Beverage” and “Green Beverage.” Those are not drinks. They are color descriptions. The shop almost certainly sells a Taro Latte and a Matcha. The model couldn’t read the labels and gave me what it could see.
These are different shapes of failure. Da Vien’s “Purple Beverage” is the model inventing a name where it should have skipped. WOOD’s $3.50 is the model returning a number that’s the wrong number — same field, same type, just wrong. I’d already shipped guardrails for the first kind: a 30-item filter that strips menu headers like "hot drinks" and "specials" from anything the model returns as a drink name. None of those guardrails would catch $3.50.
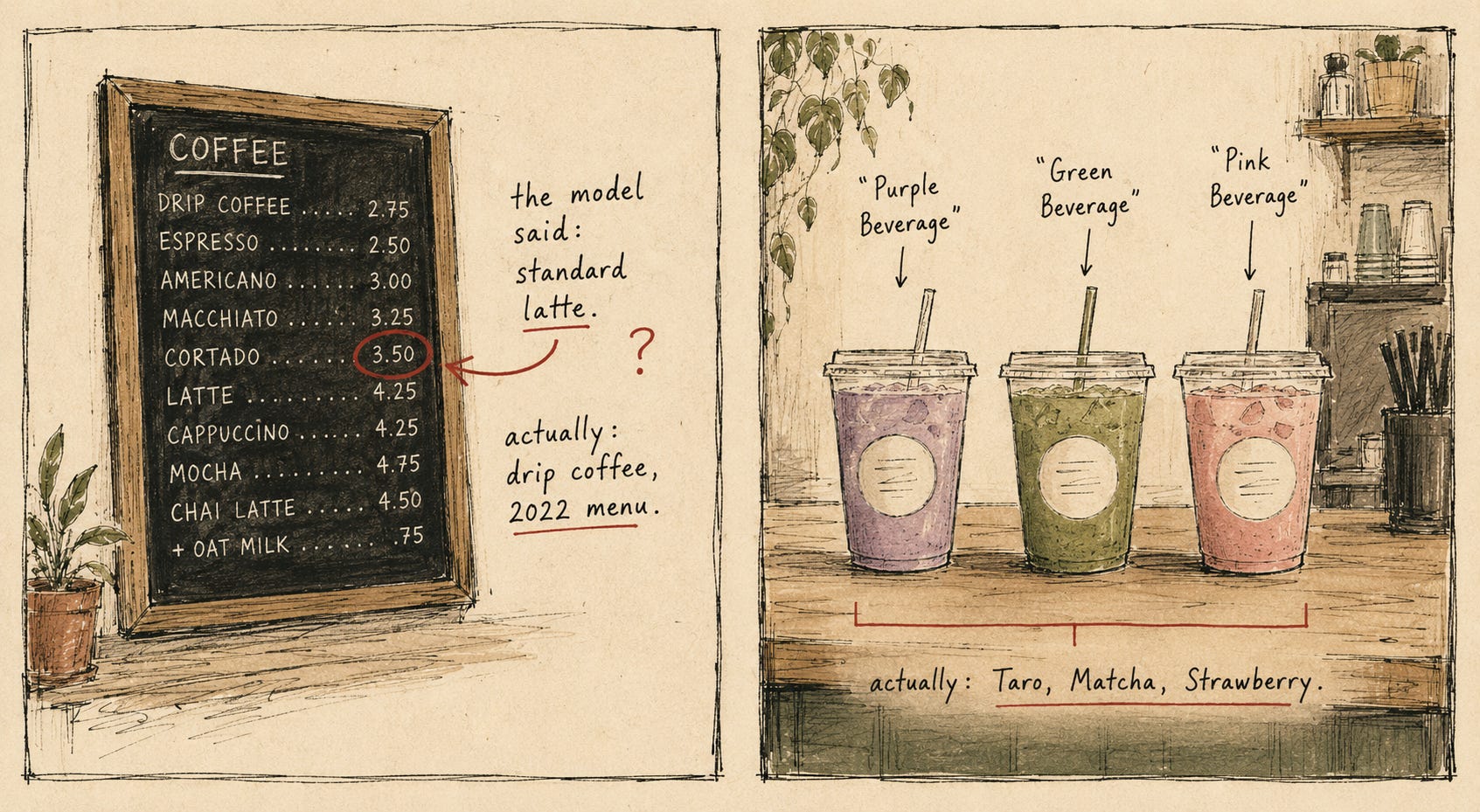
This is the actual lesson of building a metadata pipeline, and I want to land it directly: it is not a one-shot thing. Every meaningful improvement to Coffee Run’s understanding of cafés has come from running the pipeline, looking at the output, finding the place where it’s wrong or weird or surprising, and going back to the prompts or the schema or the post-hoc validators. The model is not a tagging team you fire and forget. It’s a collaborator that does the bulk work well and produces a steady stream of new failure modes for you to design around. The work isn’t writing the prompt. The work is the loop.
What the model taught me
The flip side of the failures, which is the part I didn’t expect.
Look back at WOOD’s vibes. One of them is plant-filled. That term didn’t exist in the taxonomy when I built the pipeline. It got added because the model kept telling me about it.
The vision prompt has a strict allowlist of canonical vibes. If Haiku sees something atmospheric that doesn’t fit, it’s instructed to set it aside in an escape-hatch list with evidence — vibes the model wanted to claim but didn’t have a canonical term for. I built that escape hatch expecting it to be empty most of the time. Instead, certain non-canonical vibes started showing up over and over — “plant-filled” with photo evidence of pothos on counters and hanging vines and monstera by the window, across dozens of shops. So I added it to the taxonomy. The term exists because the model essentially asked for it.
Same thing with pistachio milk. The canonical milk types are oat, almond, soy, coconut, macadamia. WOOD’s first-party pass returned ["oat", "almond", "pistachio", "soy"]. Pistachio milk turns out to be a real thing now. The model knew before I did.
This is the part that doesn’t show up on the spec sheet. Running a pipeline like this at scale gives you a passive scan of what’s actually changing in the world your product cares about — what coffee shops are doing, what their customers are noticing, what’s becoming a trend. The taxonomy doesn’t just describe the corpus. The corpus, through the pipeline, helps grow the taxonomy. That’s a kind of compounding advantage that a static Yelp tag list structurally cannot have.
On cost
The Anthropic spend on enriching every Coffee Run shop — vision, first-party, review, across the entire corpus of around 3,900 cafés, with multiple reprocessing cycles as prompts got sharper and the schema evolved — is somewhere between $100 and $500 in total. I’ll pull the exact number from the Anthropic console eventually.
The human-labor cost to produce equivalent output is orders of magnitude higher. Several full-time editors. A taxonomist to maintain the controlled vocabulary. A photo reviewer. A QA pass. Months of work. The kind of project I’d have needed to staff and budget for in my previous life building catalog products at streaming companies.
The structural point isn’t the dollar gap. It’s that the pipeline as a whole — editor, taxonomist, photo reviewer, QA, all four roles a catalog team would split up — collapses into one Haiku call, three times, with a prompt that is the policy document and a schema that is the controlled-vocabulary audit. Every claim cites a source. Every taxonomy change is a small code change, not a sprint.
This was infrastructure work last decade. It’s a side project this decade. And critically: it’s a side project that produces a data asset Yelp and Google don’t have, in a shape that lets the rest of the app do something they can’t do — match a specific person to a specific cup of coffee, on a specific morning, in a way that feels personal.
That’s the product. The pipeline is the means.
Next
I want to write next about what happens when this data hits the discovery layer — how a model-derived intent like “this is a good place to work” becomes a recommendation, and where I think indie discovery goes from here.
If you’re reading and run a shop and want to be in the database, or if you’re a builder thinking about applying any of this to your own catalog problem — say hi.